Natural Language Processing (NLP) is a key area of Artificial Intelligence focused on enabling computers to understand, interpret, and generate human language. This chapter covers fundamental and advanced NLP techniques using popular Python libraries and concepts.
Topics Covered
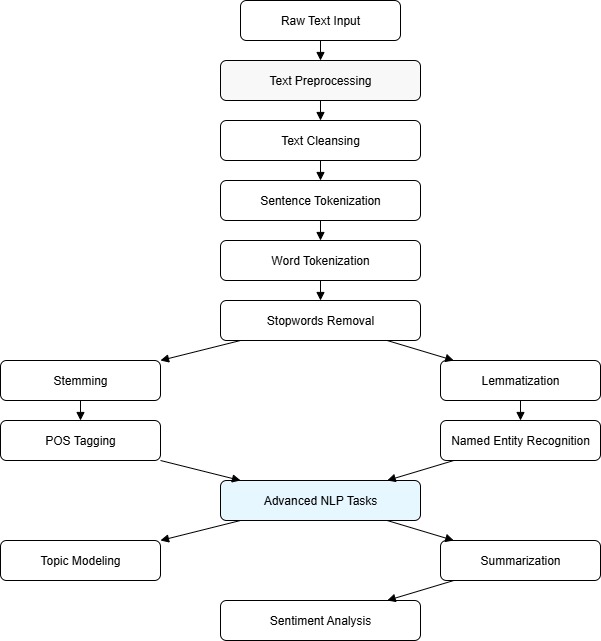
- NLTK Introduction to the Natural Language Toolkit for text processing, tokenization, and linguistic data handling.
- Text Cleansing Techniques to clean and preprocess raw text by removing noise, special characters, and irrelevant data.
- Sentence Tokenization Splitting text into sentences for granular analysis.
- Word Tokenization Breaking sentences into individual words or tokens.
- Stemming Reducing words to their root forms by stripping suffixes.
- Lemmatization Converting words to their base dictionary form considering context and part of speech.
- Stemming vs Lemmatization Comparing the two techniques in terms of accuracy and usage.
- Stopwords Removing commonly used words that add little meaning to text analysis.
- Part of Speech (POS) Tagging Identifying grammatical parts such as nouns, verbs, adjectives in sentences.
- Named Entity Recognition (NER) Extracting entities like names, places, dates from text.
- Topic Modeling Discovering abstract topics that occur in a collection of documents.
- Summarization Automatically generating concise summaries of long texts.
- Sentiment Analysis Determining the sentiment or emotional tone behind text data.
Visual Overview
Each topic is supported with practical examples and exercises to build strong foundational and advanced NLP skills.